
Context, Analysis & Impact
- Amazon’s internet infrastructure service experienced a multi-hour outage on Wednesday that affected a large portion of the internet. Read more details on The Washington Post by clicking here.
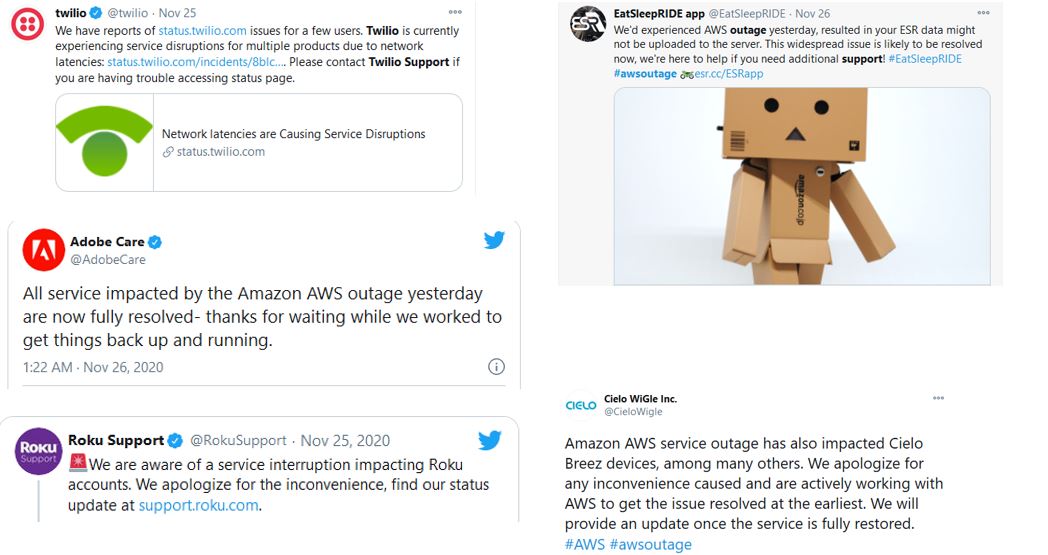
- More than 50+ companies impacted including Roku, Adobe, Flickr, Twilio, Tribune Publishing and Amazon’s own smart security division Ring, in its region covering the eastern U.S.
- Business impact such as as reported by The Washington Post:
- New account activation and the mobile app for streaming media service Roku were hampered
- Target-owned Shipt delivery service could receive and process some orders, though it was “taking steps to manage capacity” because of the outage
- Photo storage service Flickr tweeted that customers couldn’t log in or create an account because of the AWS outage
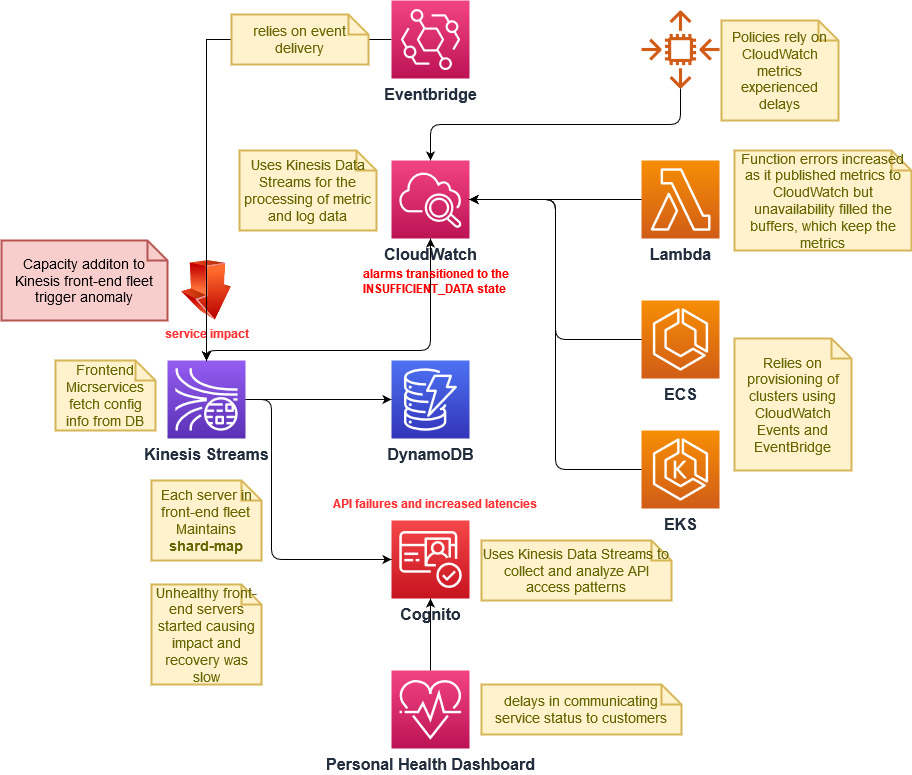
- RCA analysis by AWS – It started with Amazon Kinesis but started impacting long list of services. Read RCA document by AWS, which is also summarized below:
Lessons Learned
#1 – Don’t Put All Your Eggs In One Basket
- Using a Single Cloud Service Provider can be counter-productive in such scenarios.
- Think and strategize for Hybrid-Cloud or Private Cloud or Multi-Cloud particularly during peak season.
#2 – Not Just Think And Dry Run, Practice Disaster Recovery Often
- Don’t just rely on cloud provider’s availability and multi-region fail-over strategy, build your own resiliency and disaster recovery approach.
- Practice disaster recovery in production systems or similar by using innovative approaches in active-active setup across the multi-cloud or hybrid-cloud scenario.
#3 – Monitoring and Observability Is Not Static
- Be innovative in exploring monitoring & observability patterns. For example, if AWS is reporting an outage on their status page, your monitoring system should get into action and inform the incident resolution team to start analyzing the impact.
- Keep ready the services dependency graph – though mostly supported by tools, keep it dynamic and ready to assess the impact when it happens and map it to business functionalities to report your business team accurately.
#4 – Invest In Emerging Techniques Like Chaos Engineering
- Failure indicates that even internet giants like AWS still maturing in implementing practices like Chaos Engineering. So, start putting chaos engineering practices into roadmap.
- For example, if bulkhead pattern could have been utilized in AWS outage scenario, the outage would have been limited to Kinesis service only.
To conclude, being proactive for outages like above, having a response team equipped for unplanned outages, and improving continuously from lessons learned are essential techniques to keep the impact limited. Also, having a multi-cloud or hybrid cloud strategy is food for thought to keep the business running.
Disclaimer:
All data and information provided on this site is for informational purposes only. This site makes no representations as to accuracy, completeness, correctness, suitability, or validity of any information on this site and will not be liable for any errors, omissions, or delays in this information or any losses, injuries, or damages arising from its display or use. All information is provided on an as-is basis.This is a personal weblog. The opinions expressed here represent my own and not those of my employer or any other organization.
This is very informative. Thanks.