
Evolution of Caching Technologies
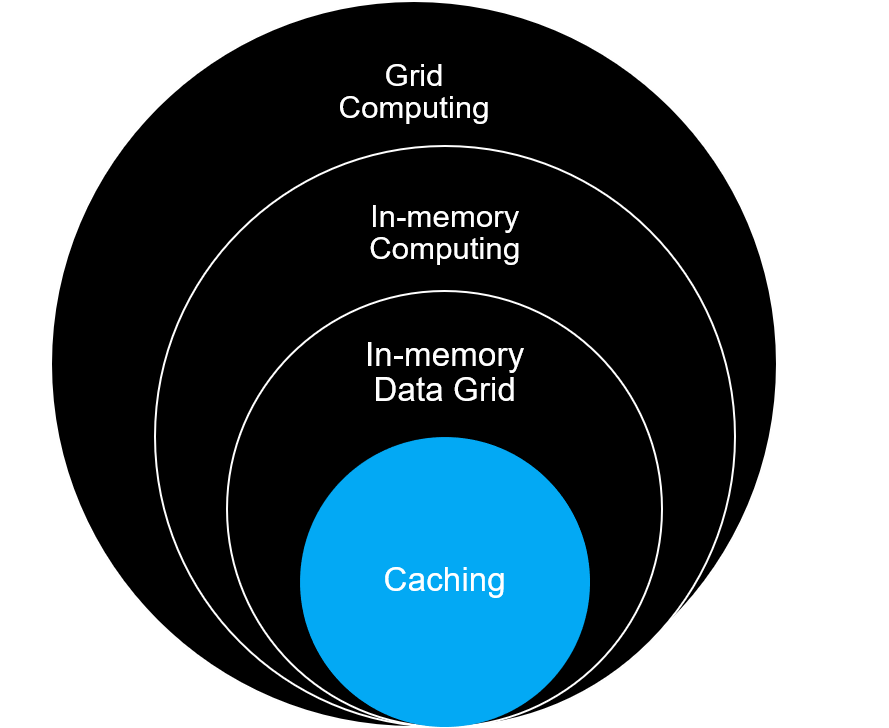
In an early stage, caching started with simply putting data into memory (mostly as local cache) in the same processing node (usually an application server). Gradually it evolved with externalizing the cache as a separate process and eventually re-engineered towards distributed computing architecture. In the current landscape, most of the caching system architecture uses in-memory data grid technology, which is essentially a part of in-memory computing with grid computing as the underlying architecture.
The complexity of managing a distributed caching system necessitated the re-architecture of caching solutions and the complexity of patterns increased. This led to various distributed caching patterns evolving for different industries solving complex business use-cases focused on high performance & high throughput. With increasing data versatility, volume, and real-time processing need, the data platforms have started leveraging in-memory compute and storage as integrated technology.
Essentially, this elevated Caching as a concept towards in-memory compute and storage, and hence this is why Caching and in-memory data grid is no longer an afterthought in modern architecture. It not only handles modern architecture requirements but also takes it to new levels by improving system resiliency, scalability & availability, and elevates user experience driving business value.
Caching Use-cases
Caching is based on Write-Once, Read-Many in-memory design paradigm, which helps in designing highly scalable and high-performance distributed applications. Below are a few examples of applying Caching to achieve measurable business results:
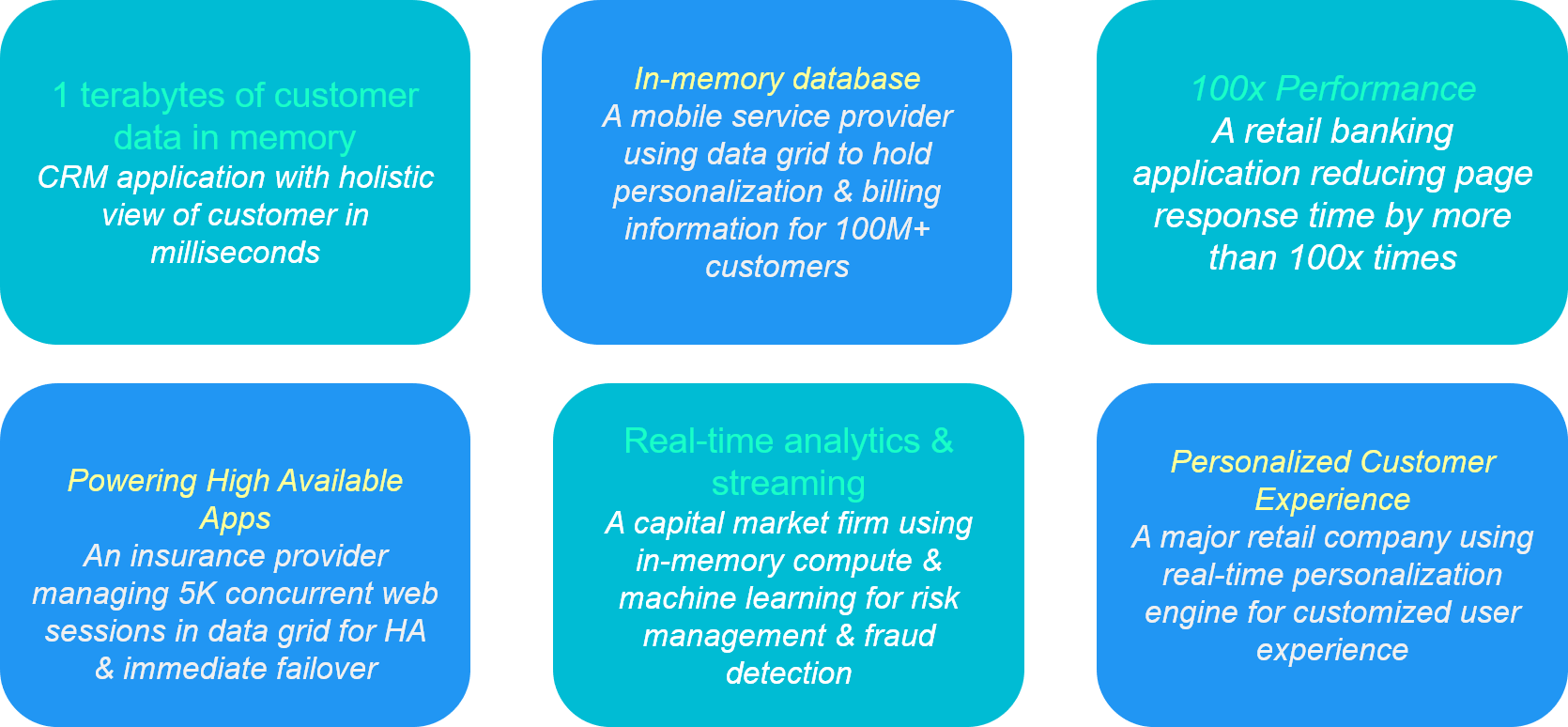
Benefits of Caching & In-memory data grid
While Caching has also been considered as an enabler for highly scalable and high-performance applications, it also helps to:
- Reduce load on backend datastores by heavy-lifting high-volume requests & bringing cost-efficiency in terms of database costs
- Support for Write-once and Read-many for up to 100x quicker retrieval in comparison with a database
- Support streaming ingestion with integration to streaming-processor platforms like Spark, Kafka, etc.
Scale-out translytical architecture (term coined by Forrester for unified data platform to perform multiple workloads within a single database) for combined optimized transactions & analytics processing
Difference between Caching & In-memory data grid
Another key aspect is to differentiate between In-memory distributed caching, and In-memory distributed data grid.
In-memory distributed caching is to cache frequently accessed data and distribute it across caching nodes for high-availability, whereas in-memory data grid adds compute capability so that computation on large data-set can happen closer to data. Data processing capability differentiates the two different paradigms.
Caching Basics – How it Works?
While it is not complex to understand Caching as a concept, there are four key steps in a typical caching implementation:
- Step 1 — Cache Design: While the end-to-end cache strategy helps at the architecture level, individual caches need to be designed to meet the requirement. Cache type and deployment topology need to be proactively determined with current and future state consideration.
- Step 2 — Cache Operation: Caching starts with a simple PUT operation (Key/Value pair), but the complexity is hidden from the cache client in terms of managing a distributed caching system.
- Step 3 — Cache Distribution: Most of the high-available caching systems operate in distributed mode using a multi-master setup and replicating cache data (in shards) across cluster nodes.
- Step 4 — Cache Maintenance: Maintenance of cache (e.g. cache eviction approach, time-to-live, etc.) also plays an important role in overall cache capacity as by design cache should be ephemeral. A long-lived caching solution is an emerging pattern where Cache is being even considered as reliable storage for maintaining critical data elements.
Caching Types
While determining the caching strategy, cache types play a vital role in determining the deployment strategy. Though it is also dependent on the underlying implementation or out-of-the-box product, these are usual cache types:
- Local Cache — Most basic form where the cache is local to (completely contained within) a particular processing node.
- Distributed Cache — Cache data gets partitioned across the nodes to ensure there is at least one primary and multiple secondary cache (in case of a failover) is available.
- Replicated Cache — Cache data gets fully replicated to every node in the cluster. While this provides the fastest read performance, it has poor scalability for writes as data replication and consistency take longer.
- Optimistic Cache — It is similar to the replicated cache without concurrency control and offers higher write throughput than a replicated cache.
Caching Patterns
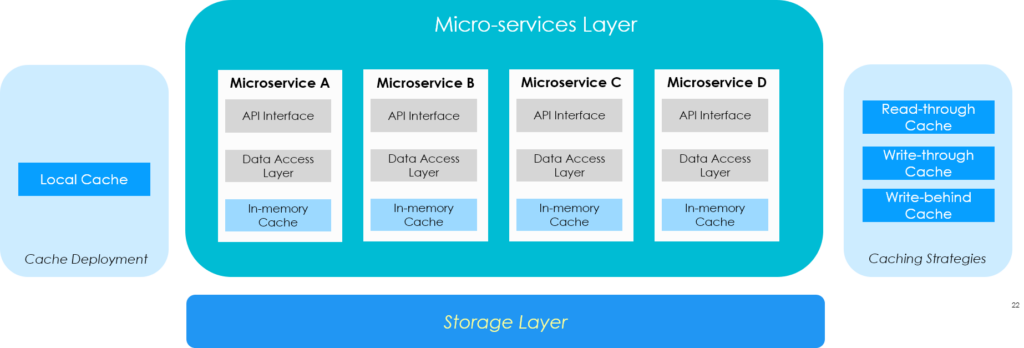
Caching is not only limited to a single layer or tier in multi-tier application architecture. Modern architecture practices recommend applying caching patterns at each tier in the system architecture. Below is an example of applying caching in a typical web application architecture:
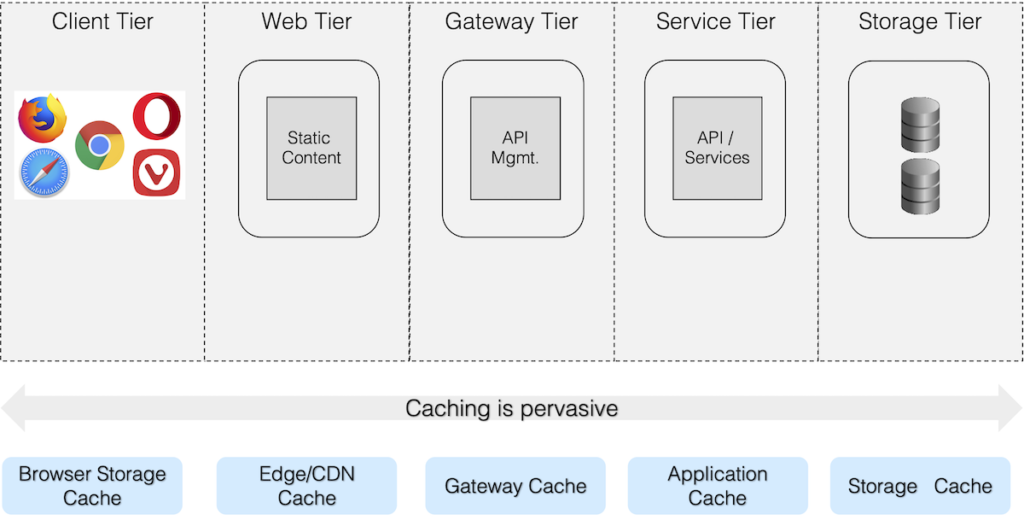
Application Caching Patterns
While caching at each tier is a broader subject area, this section outlines two key patterns applicable at the application tier. Application-level caching is the most common caching scenario in modern architecture.
Pattern A – Using Caching as an enterprise in-memory data grid
It starts with establishing a shared caching or in-memory data grid layer, which abstracts the underlying complexity. The application tier can simply interact with the data grid layer as a client and delegate all the complexity of cache management to it.
Applicability:
- For application caching ensures sub-millisecond response time, high read performance, and offload resource contention from the storage layer.
- The enterprise-wide applicability applies using the in-memory grid for multiple applications.
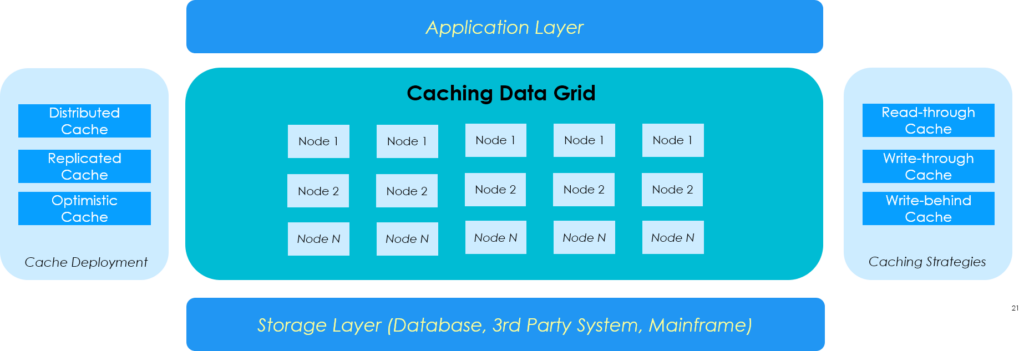
Pattern B — Using Cache embedded with the application stack
Approach: Use a minimal micro-cache (deployed alongside micro-service application as a sidecar) without any distributed caching
This approach recommends caching node be kept closer to the client (i.e. application tier) and possibly in the same machine or VM or POD (if you are using Kubernetes). Consider that caching is running as a separate process or container but it is not distributed or clustered.
Applicability:
- For application caching (mostly as L1/L2 level caching) for limited caching (scalability limited) requirements.
- Use a minimal micro-cache without any distributed caching (each service has its copy of cache data)
Out-of-the-box Caching Products
To implement caching patterns with a focus on time-to-market, choosing a suitable caching product is key to the successful rollout of caching strategy. The open-source community has played a vital role in building enterprise caching products with support for both in-memory caching and in-memory computing applying grid computing. Also, cloud service providers ( AWS, Azure & GCP) have partnered with most of these vendors to offer both public, private or hybrid deployment solution options:
- Hazelcast — evolved as a streaming and memory-first application platform from caching solution
- Redis — a real-time database with high-performance caching for your business-critical applications.
- Apache Ignite — evolved as a distributed database for high-performance applications with in-memory speed.
- Oracle Coherence — an in-memory data grid solution that enables the creation of scalable mission-critical applications.
- GigaSpaces — evolved as a data platform adding caching layer between the database and the application.
Also, primary cloud service providers also have similar offerings such as:
- AWS ElasticCache — Fully managed service by AWS with automated provisioning with support for Redis & Memcached
- Azure Cache — Fully managed service by Azure with automated provisioning with support for Redis
- Google Cloud Memorystore — Fully managed service by Google Cloud with support for Redis & Memcached
To conclude, the evolution and the role of caching in modern architecture indicate why caching and in-memory data grid is no longer an afterthought. It needs to be thought through during the architecture & design phase to ensure high performance, high availability, and high scalable application. Focusing on what to cache, where to cache, how to cache, how long to cache, and most importantly why to cache, helps to apply the suitable practices before the caching implementations.
Please share your view, experience, and learning as comments. Keep experimenting!
RELATED ARTICLES
- Top Ten Trends You Should Know as a Modern Software Architect
- Modern Technical Buzzwords You Should Know As A Software Architect
- 5 Books Every Architect Should Read
- Top Ten Technology Trends 2021